What’s on our mind: How modern search tools are changing library cataloguing
Last updated on: 24th June 2026| 24th June 2026 | Sam Goldsmith | Koha
The evolution of search in Koha
For decades, cataloguing has been dominated by the meticulous task of manual subject indexing. We spend countless hours ensuring that every potential keyword is represented in a machine-readable cataloguing (MARC) record, fearing that if we do not, the item will not be found by our patrons.
Some very popular library management systems have very bad reviews for even finding a full title in basic search. These platforms regularly fail to find items due to punctuation and slight spelling errors, all of which we know are likely to occur when our patrons run a search.
Let us look at some issues that arise without a modern search engine:
- Titles can be plagued by ‘stop words, ignored words, or operator words’ such as ‘To Be or Not to Be’.
- Titles with punctuation, symbols, or numbers require an exact match to how they were catalogued.
- Legacy engines suffer from diacritics and normalisation issues, treating characters with accents as entirely different strings or completely stripping them without mapping them back to their base characters.
- Non-alphanumeric characters either require an exact match or break the system entirely upon encounter.
- Queries with typos lack fuzzy matching, meaning a misspelt author name can break the search.
- The system fails to find a key subject when it is not explicitly mentioned in the title.
- The engine fails to group the same title editions and different media types together.
However, we are entering a new era. By leveraging the power of an enterprise-grade search engine, we can move away from manual keyword input and toward a system where our existing data works much harder for us.
The limitations of the Zebra engine
To understand where we are going, we must look at where we have been. For a long time, Koha LMS has relied on the Zebra engine. Zebra is incredibly ‘biblio-centric’, meaning it was built specifically to index MARC data. Many proprietary systems use this type of index.
Zebra is often described as a ‘black box’. Customising how it indexes or retrieves data is a heavy lift that requires expert knowledge. This complexity often meant that if a search was not working, the only solution for a cataloguer was to add more manual subject headings and hierarchies to the record itself. This becomes a real issue for smaller services or those without specialist staff.
Many systems attempt to solve these issues by enhancing library-side search operators like Boolean, which only serves to complicate the search. We must acknowledge that most searches take place without staff support, and if that first search fails, a large number of patrons will abandon their efforts.
If patrons need a detailed search tutorial to find anything, that wastes valuable time that could be used to support them in more important ways, or could deter them from making the search in the first place. Advanced search tools should be an addition to a successful search, alongside traditional filters and ways to refine the hits. Your system should help your patrons rather than hinder them.
Elasticsearch and SOLR: Enterprise power for libraries
Elasticsearch is a massive, enterprise-grade search engine used by global internet platforms like Wikipedia, Facebook, eBay, and GitHub. It is a global standard for discovery rather than just a library tool. Our supported open source discovery tool, Aspen Discovery, also benefits from a modern, web-type search engine called SOLR.
Advances with modern search engines
Modern search engines offer several critical advancements straight from the simple search box:
- FRBRisation: This process successfully groups different media and editions of the same title together.
- Spelling help and prediction: This feature uses fuzzy matching to ask ‘do you mean’ or suggest alternative topics.
- Flexible fuzzy matching: This allows for out-of-order titles, meaning patrons do not need to use Boolean or search symbols to find a title. For example, searching ‘The Fellowship of the Ring’ or even ‘lord of the ring’ will find relevant items in that series, despite misspellings and omitted keywords.
- Comprehensive synonym lists: An extensive synonym list comes as standard, covering variations like American vs UK English so you do not need to build this yourself.
- Custom weighting: The engine still allows libraries to add weighting for specialist topics or local synonyms.
Of course, patrons can still utilise more advanced search options, operators, and filters, but the key point is that the first search is far more likely to be successful.
Elasticsearch brings a modern search syntax that aligns with what our users expect today. It understands the difference between terms and operators. For example, it recognises that ‘The World Is Not Enough’ is a title, while ‘The World Is NOT Enough’ contains a Boolean operator. It also defaults to an ‘AND’ operator, which is much more intuitive for patrons accustomed to modern search engines. Additionally, it will successfully find a record that matches a full title search and place it at the top of the results, even when a general search has been executed.
Search configuration and customisation
The power of Elasticsearch lies in its ‘Search Engine Configuration’ page, located directly within the Koha staff client. Library staff can now determine exactly which fields are searchable and apply ‘weight’ to those fields. This capability is vital in libraries and archives that handle specialist terminology.
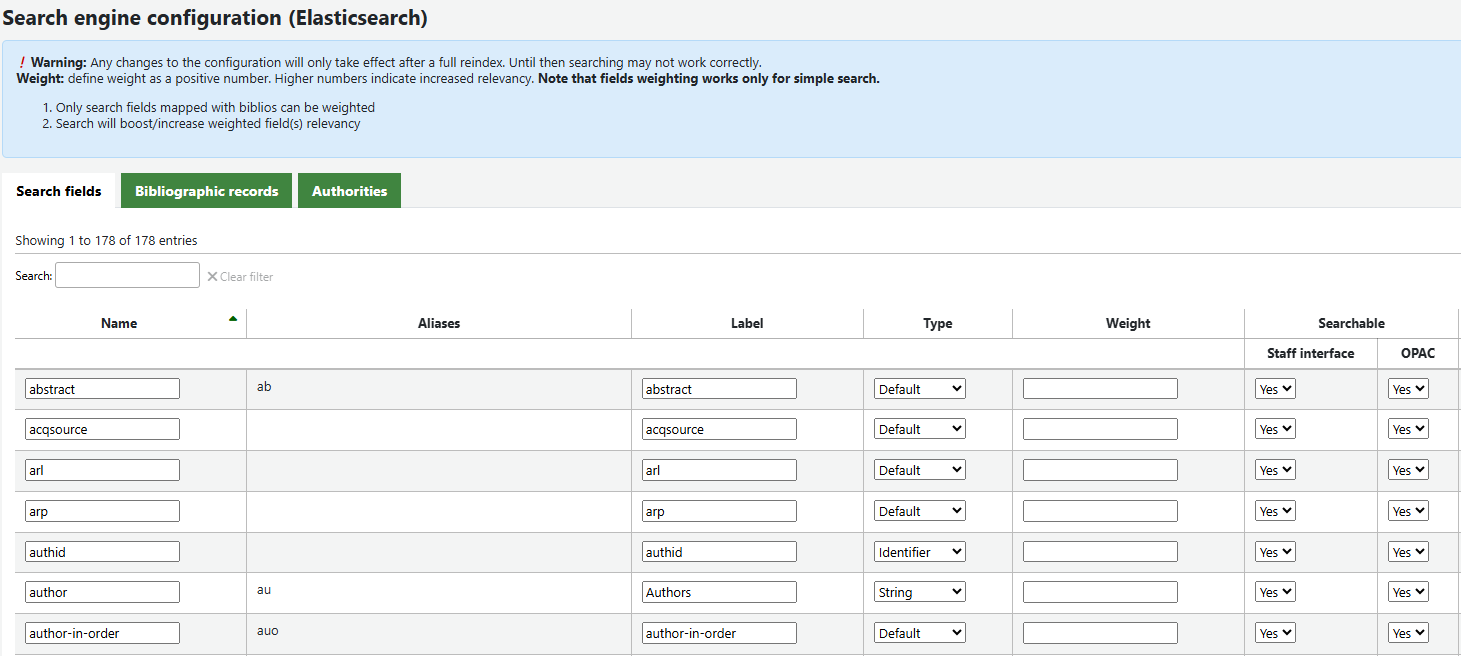
If a term appears in a title, we can weight it more heavily than if it appears in a general note, ensuring the most relevant results rise to the top. We can even configure indexing down to the individual subfield level.
Because the engine is so flexible and powerful at retrieving information from all existing MARC fields, the need for manual subject and keyword work is significantly reduced. Instead of being limited to what we manually type into a keyword field, searches are optimised by how we choose to configure the engine to make our collections visible.
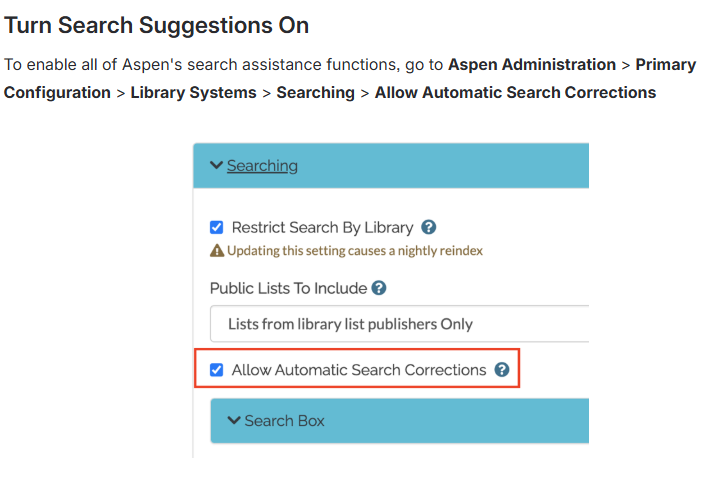
Aspen also offers various simple one click settings to enhance search – such as this one to turn on fuzzy/suggestions:
The future of cataloguing workflows
The meticulous subject indexing of the past was a direct response to the limitations of our search tools. It served as a necessary but time-consuming step to ensure the resources libraries spent vital funds on were successfully found and used.
When migrating from other legacy systems to Koha LMS, customers often panic about losing extensive subject and keyword data. We always safely migrate these records, but in almost all cases, our new customers soon relax this intense workflow for new stock. It quickly becomes clear that Elasticsearch automatically does this heavy lifting for them, pulling keywords from abstracts alongside the usual MARC fields. This effectively frees cataloguing staff to concentrate on unique items that lack traditional MARC metadata.
Ultimately, the shift to Elasticsearch represents a significant search transformation. Libraries can provide superior discovery with significantly less manual labour, and patrons receive a simple, familiar search experience that consistently delivers what they need on the first page of results.
Blog post featured image: Cyathea dealbata by Krzysztof Ziarnek, Kenraiz published under the Creative Commons Attribution-Share Alike 4.0 International license. (Source: Wikimedia Commons)

