What’s on our mind: Fighting the AI bots
Last updated on: 4th July 2025| 23rd June 2025 | Open Fifth | WOOM
The background on AI bots
Since around March this year we have seen a significant increase in the amount of bots crawling our library sites. The majority of this has been AI bots. In the past, a website could deploy a file called “robots.txt” which would indicate to search engines like Google, Bing, etc. whether they were allowed to crawl a site or not (and which parts of that site). This was often useful as libraries would like to surface (or block!) their content in search engines. However, it now seems that the rush to create AI LLMs has led to AI bots disregarding this file and sending vast quantities of requests without asking for permission or with consideration to site performance. As an example, at one point recently, we collected and categorised all the /24 ranges (groups of 255 IP addresses) from the 3000+ connections that had hit the server in a period of 15 minutes, and there were over 2700 different network subnets.
We noticed a secondary pattern – that the requests were coming from older browser ‘user agents’ (how web browsers identify themselves – Chrome 135, Firefox 129, etc.) – these abusive platforms use different user agent strings to prevent ‘patterns’ of usage being obvious, but they often aren’t very sophisticated about it; in the past months we’ve seen user agents from Windows CE devices for example, they’re just picking user agents at random. Having managed to mitigate older user agents, in recent weeks these platforms have realised that they are being blocked and have re-emerged with more realistic user agent strings.
Their impact
The consequence of the above is that we have seen many of the library sites we support inundated with requests. Each request is from a different IP address and typically from a different location in the world. At this point our traditional methods of blocking traffic (that is, by IP address) become totally ineffective. This causes site slow-down and, potentially, the server being unable to cope with the load.
This is NOT a problem which is unique to us. Millions of sites around the world have been suffering from the same. If you’d like to read more, here are a couple of interesting articles:
Mythic Beasts, April 2025 – Abusive AI Web Crawlers: Get Off My Lawn
Nature, June 2025 – Web-scraping AI bots cause disruption for scientific databases and journals
TechCrunch, March 2025 – Open source devs are fighting AI crawlers with cleverness and vengeance
Ars Technica, March 2025 – The Great Flood: Open source devs say AI crawlers dominate traffic, forcing blocks on entire countries
Library catalogues are a particularly attractive source of information as they contain rich metadata. Also, library catalogues typically contain many linkages, subject headings, author names, series titles, etc. for each record which means bots can pretty much carry on endlessly jumping from link to link or just firing search queries at the catalogue.
Fighting back
We’re having to find new ways of fighting back against these attacks (which are really the equivalent of denial of service (DDoS) attacks).
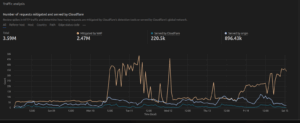
Cloudflare – This is a content delivery network service (CDN). Cloudflare acts as a protective and performance-boosting layer between your library application and the internet. Traffic passes through it on the way to your library system and Cloudflare provides performance optimisation and security protection. We have been using it for a few years now and continue to tune it to work efficiently with third party services like discovery systems, ebook suppliers, SIP2 devices and so on. We’re getting great results from it where it is enabled. Below is a chart which shows (over a period of 7 days) the impact of our efforts to block AI bots via Cloudflare. You can see that the domain received 3.59M requests over 7 days of which only half were legitimate.
Apache web server configuration – This is a fairly blunt tool in our toolbox. We have been adding rules to the web server configuration to block browsers who identify themselves as more than 2 years old. The vast majority of devices these days force you to keep your browser up to date so this has worked pretty well for us. We’ve had a few exceptions. Library patrons who are on really old equipment, library devices with old software(!) and also some third-party library vendors who also identify themselves as old devices. We have been fine-tuning the rules to accommodate these exceptions.
Anubis – This is a new tool in our armoury. Anubis has gone viral because of all the reasons discussed above. It is an open source project which uses complex algorithms to look at the behaviour of the web request in order to try and identify whether a request is genuine or not. It does this by flashing up a challenge on the screen. Unlike a Captcha, you do not have to interact with it. In most cases the challenge will have flashed past you before you have the chance to read it. We’ve put one on a Koha system here, see if you are quick enough to spot it!
We have actually sponsored this open source project on GitHub as we think it adds real value as a tool and it’s also a tool that we are keen to support and deploy. We’re working with a couple of libraries to trial it and results so far are very exciting. For example, we put it on one library catalogue last week. This means it has been active on the site for approximately two working days (and a weekend). During that time it has issued over 45,000 challenges (that is web requests). Of those, around 800 have been let through. That means 98% of the requests coming into the site are automated requests (likely AI bots). Only 2% are genuine!
Where now?
This is an ongoing battle, it is consuming something in the region of 20% of the time of our systems team right now. This is time we’d rather spend working on your support tickets and projects for libraries! So, we’d love to work with you to make your sites more robust. The reason we have multiple solutions described above is that we have multiple scenarios. In many cases libraries are using our domains and we have the ability to control and protect these with our Cloudflare. However, in other cases libraries are using their own domains (vanity domains), e.g. xxx.universityname.ac.uk. The protection of the DNS traffic here is not in our control, it is only in the gift of the domain owner to protect it.
We are typically finding that ‘.ac.uk’ domains are at higher risk of being attacked, presumably due to their high reading-age content which is better for language models to ingest. Although academic institutions have rigorous rules in place to protect their networks, we are finding that the DNS records for externally hosted applications (such as Koha) aren’t capable of being protected in the same way and so end up getting hit by these bots quite a lot.
So, our options:
Open Fifth domains – that is, https://xxx.koha.openfifth.net/, https://xxx.koha-ptfs.co.uk/, https://xxx.aspendiscovery.co.uk/. All these domains we can put behind Cloudflare to protect.
Institutional (vanity) domains – that is, pretty much anything with an .ac.uk domain, .gov.uk or your organisational name, which we do not own and thus we cannot protect with Cloudflare. However, we can put Anubis on these systems and we would like to begin rolling this out as soon as possible.
Moving forward
At the start of July 2025 we are going to start actively deploying the above solutions to your systems (where they are not already in place). It will likely take us 3 months to get to all systems. There is no action on you other than to let us know if you have any third-party systems accessing your system that you think we should be aware of – it will only impact them if they use HTTP/S connections, so don’t worry about SIP devices.
We will send you an email when we are about to enable one of these solutions on your system (just in case you do notice any difference in behaviour). However, the site should appear as normal. It should be noted that to support the author of Anubis, we have a white label implementation, so the ‘checking’ and ‘verified’ screens have simple icons, not a cute chibi Egyptian god!
Some brief thoughts on AI
AI has arrived on the scene at what seems like an unbelievably fast pace! I’m sure, like us, you are being offered all sorts of “AI-enabled” services. The people who aren’t looking to solve the problems described above are, of course, AI companies – which includes some of the biggest names in tech, who would regularly be the sort of companies to come up with solutions for this problem, if it were someone else!
It does feel a bit like the Wild West out there right now with all sorts of organisations looking to build LLMs with no consideration for copyright ownership nor the rights of creators. Aside from the digital rights and wrongs of crawling, there are the huge environmental impacts of artificial intelligence. This involves substantial energy consumption for training, the carbon footprint this leaves behind, as well as the huge water footprint required to cool AI servers. You won’t find that in the advertising brochure! That said, we also understand the potential that AI can offer now and in the future – it’s a fine line to walk.
As a company who work in technology we have been having discussions with all our staff on how they use AI in their daily lives and whether they see that there are genuine added benefits of adding AI to our applications. We don’t want to add AI just because everyone else is doing it. I’m sure you’ll hear more about this from us in the near future.
Check out our recent What’s on our Mind post ‘Exploring AI in open source library software‘ for more information.
Update : 3rd July 2025 – We thought you might also be interested in this article from Duke University which describes the huge success they have had running Anubis in front of their catalogue, archives and repository. Libraries in particular seem to be turning to Anubis, we have also seen it in use at Columbia University Libraries and University of California, Los Angeles (UCLA). A side-effect that is mentioned in the article is better overall performance for “real” users of the library and that is certainly a positive side-effect we are noticing on our systems as well.
In discussion, Jonathan Field, Managing Director (JF), and Steven Raith, Head of IT (SR)
JF – So, everyone is talking about AI, how is it affecting and impacting the day-to-day life of Open Fifth at the moment?
SR – We understand the pros and cons of AI but, as a system team supporting libraries we are seeing increased load on our servers, causing performance issues for our clients, and causing our infrastructure team sleepless nights. But at least Facebook on mobile can suggest inappropriate questions to ask about articles I’m scrolling past!
Sarcasm aside, it’s a handy tool for ‘combined documentation’ – for example, it’s read all the articles on StackExchange, a forum for systems administrators, and can give pretty concise and sometimes even pretty accurate answers on fairly obscure topics. There’s absolutely an application for it.
JF – So, practically, what is the impact on the libraries we support (and I guess on other websites around the world)?
SR – At the moment, a significant proportion of the internet is being scraped by dozens – if not hundreds – of crawlers designed to collect data for Large Language Models, because that’s currently the “Big Thing” for venture capital funding. This was less of a problem when it was just AWS, Google and Anthropic doing it because they would identify themselves, would generally not scrape too hard, and if they misbehaved, we could tell them to stop – and they’d listen.
Now, however, it seems that organisations have started using subcontractors to scrape the internet for them and they are… let’s say, less well mannered. They explicitly lie about who they are, and they use far too many resources when scraping – sometimes hundreds of connections per second. Unless you are running a website with huge resources or very carefully tuned content provisioning toolchains, it just brings the site to its knees, every time.
The problem is that a simple website just serving text doesn’t get affected much – but Koha is a multi-system stack of Apache, Perl and MySQL running on Linux – every request you make takes a couple of tenths of a second for that stack to return the correct value (say, a search result). Multiply that by a hundred times and you start to see where the problem comes in.
And it’s not just libraries of course – I have technical contacts in a variety of industries who are dealing with the same problems.
JF – I know the infrastructure team at Open Fifth have been working hard to resolve this. What sort of measures can we put in place to protect our libraries
SR – For domains we have control of – openfifth.net, koha-ptfs.co.uk, aspendiscover.co.uk, etc. Cloudflare works nicely. Cloudflare is a name most will recognise as on the rare occasions they have a problem, everyone notices because they protect a significant proportion of the internet against traffic like this.
For domains we don’t have control of we have been trialing Anubis. Anubis is working very well – it forces your browser to do a little (to it) bit of hard maths to prove it’s a real computer. The bots are usually running with extremely low resources to get the most bang for buck out of the hardware they’re being run from, so that maths takes them…. well, they can’t really do it! Anubis weighs the soul of the connection being made – because it’s Anubis, you get it? – and then sets a cookie in the browser for the real users, so they don’t get hit with its challenge every time they load a page.
JF – What sort of results are we seeing from that?
SR – On one academic institution, we told Anubis to ignore any connections from the JANET networks, and only to challenge requests from outside of there – so mobile phones, our internet, etc. 99.99% of those requests didn’t complete the challenge.
19 out of 75,000 requests got through. In eight hours
With respect to Cloudflare, one client had a site getting a million hits a week. About a thousand of which were genuine.
Which should illustrate the scale of the problem.
JF – What’s going to happen in the coming months?
SR – At the moment we’re in what I’ll call a Beta phase with Anubis – it’s feature complete, but we’re catching edge cases. We have a lot of knowledge of what those edge cases are from our work with Cloudflare (we’ve been running that quietly in the background for quite a few clients who have a technical interest in this and could accept reporting erroneous blocks to us) so the broad plan is that we’ll start adding more systems to Cloudflare where we are able to, and for systems outside of our control from a DNS perspective, we’ll initially be adding Anubis to sites where we can see they are clearly getting hammered by bots, before likely making it part of our default setup.
Longer term, as we have a relationship with the developer of Anubis, we may have a conversation with them about perhaps integrating it more tightly into Koha – perhaps as a ‘default configuration option’ in the Anubis package, or perhaps seeing how feasible it is to make it a plugin.
This is all very much long term thinking though – I’m fairly certain that as the MD and a founder of the company, you would, much like our clients, like for my team to be doing our actual job of handling support tickets, helping with projects and implementations, doing research, and maintaining our security and quality certifications rather than batting this computationally expensive white noise away from our infrastructure.

